Maximum Likelihood
Maximum Likelihood¶
Suppose you have an i.i.d. sample $X_1, X_2, \ldots, X_n$ where the density of each $X_i$ depends on a parameter $\theta$.
Assume that $\theta$ is fixed but unknown. The method of maximum likelihood estimates $\theta$ by answering the following question:
Among all the possible values of the parameter $\theta$, which one maximizes the likeihood of getting our sample?
That maximizing value of the parameter is called the maximum likelihood estimate or MLE for short. In this section we will develop a method for finding MLEs.
Let's look at an example to illustrate the main idea. Suppose you know that your sample is drawn from the normal $(\mu, 1)$ distribution for an unknown $\mu$, and you are trying to estimate the value of $\mu$. Suppose the sampled values are 52.8, 51.1, 54.2, and 52.5.
That's a small sample but it carries information. If you had to choose between 32 and 52 as values for $\mu$, which would you choose?
Without any detailed calculations it's clear that 32 is not a good choice – the normal $(32, 1)$ distribution is unlikely to produce values as large as those in the observed sample. If 32 and 52 are your only two choices for $\mu$, you should choose 52.
But of course $\mu$ could be any number. To find the best one, you do have to do a calculation.
MLE of $\mu$ Based on a Normal $(\mu, \sigma^2)$ Sample¶
Let $X_1, X_2, \ldots, X_n$ be an i.i.d. normal $(\mu, \sigma^2)$ sample. The sample mean is a pretty good estimate of $\mu$, as you know. In this example we will show that it is the maximum likelihood estimate of $\mu$.
What if you want to estimate $\sigma$ as well? We will tackle that problem at the end of this section. For now, let's just estimate $\mu$.
The Likelihood Function¶
The likelihood function is the joint density of the sample evaluated at the observed values, considered as a function of the parameter. That's a bit of a mouthful but it becomes clear once you see the calculation. The joint density in this example is the product of $n$ normal $(\mu, \sigma^2)$ density functions, and hence the likelihood function is
$$ Lik(\mu) ~ = ~ \prod_{i=1}^n \frac{1}{\sqrt{2\pi}\sigma} \exp \big{(} -\frac{1}{2} \big{(} \frac{X_i - \mu}{\sigma} \big{)}^2 \big{)} $$The quantity $Lik(\mu)$ is called the likelihood of the data $X_1, X_2, \ldots, X_n$ when the mean of the underlying normal distribution is $\mu$. For every fixed $\mu$, $Lik(\mu)$ is a function of the sample and hence is a random variable.
You'll soon see the reason for using the strange notation $Lik$. Please just accept it for now.
The goal is to find the value of $\mu$ that maximizes this likelihood function over all the possible values that $\mu$ could be. We don't yet know if such a maximizing value exists, but let's try to find it anyway.
To do this we will simplify the likelihood function as much as possible.
$$ Lik(\mu) ~ = ~ \big{(} \frac{1}{\sqrt{2\pi}\sigma} \big{)}^n \exp \big{(} -\frac{1}{2\sigma^2}\sum_{i=1}^n (X_i - \mu)^2 \big{)} ~ = ~ C \exp \big{(} -\frac{1}{2\sigma^2}\sum_{i=1}^n (X_i - \mu)^2 \big{)} $$where $C$ doesn't depend on $\mu$ and thus won't affect the maximization.
Even in this simplified form, the likelihood function looks difficult to maximize. But as it is a product, we can simplify our calculations still further by taking its log.
The Log Likelihood Function¶
Not only does the log function turn products into sums, it is an increasing function. Hence the value of $\mu$ that maximizes the likelihood function is the same as the value of $\mu$ that maximizes the log of the likelihood function.
Let $L$ be the log of the likelihood function, also known as the log likelihood function. You can see the letter l appearing repeatedly in the terminology. Since we'll be doing most of our work with the log likelihood function, we are calling it $L$ and using $Lik$ for the likelihood function.
$$ L(\mu) ~ = ~ \log(C) - \frac{1}{2\sigma^2}\sum_{i=1}^n (X_i - \mu)^2 $$The function $L$ looks much more friendly than $Lik$.
Because $\log(C)$ doesn't affect the maximization, we have defined a function to calculate $L - \log(C)$ for the sample 52.8, 51.1, 54.2, and 52.5 drawn from the normal $(\mu, 1)$ distribution. Remember that we began this section by comparing 32 and 52 as estimates of $\mu$, based on this sample.
sample = make_array(52.8, 51.1, 54.2, 52.5)
def shifted_log_lik(mu):
return (-1/2) * sum((sample - mu)**2)
Here is a graph of the function for $\mu$ in the interval $(30, 70)$.
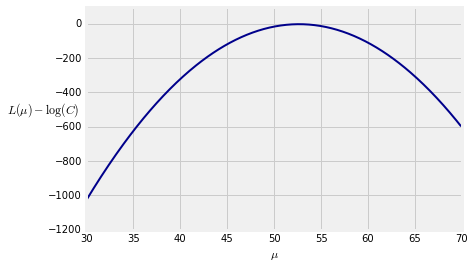
The maximizing value of $\mu$ looks very close to 52.5. To find exactly where it is, we will find the derivative of $L$ with respect to $\mu$ and set that equal to 0.
Derivative of the Log Likelihood Function¶
Use the Chain Rule and be careful about negative signs.
$$ \frac{d}{d\mu} L(\mu) ~ = ~ \frac{2}{2\sigma^2} \sum_{i=1}^n (X_i - \mu) $$Set Equal to 0 and Solve for the MLE¶
Statisticians have long used the "hat" symbol to denote estimates. So let $\hat{\mu}$ be the MLE of $\mu$. Then $\hat{\mu}$ satisfies an equation:
$$ \sum_{i=1}^n (X_i - \hat{\mu}) ~ = ~ 0 ~~~~~~ \Longleftrightarrow ~~~~~~ \sum_{i=1}^n X_i ~ = ~ n\hat{\mu} ~~~~~~ \Longleftrightarrow ~~~~~~ \hat{\mu} ~ = ~ \frac{1}{n} \sum_{i=1}^n X_i ~ = ~ \bar{X} $$We should check that this yields a maximum and not a minimum, but given the answer you will surely accept that it's a max. You are welcome to take the second derivative of $L$ and check that we do indeed have a maximum.
We have shown that the MLE of $\mu$ is the sample mean $\bar{X}$, regardless of the population SD $\sigma$. In the case of the sample we used for the plot above, $\bar{X} = 52.65$.
np.mean(sample)
You know that the distribution of $\bar{X}$ is normal with mean $\mu$ and variance $\sigma^2/n$. If you don't know $\sigma$, then if the sample is large you can estimate $\sigma$ by the SD of the sample and hence construct confidence intervals for $\mu$.
Steps for Finding the MLE¶
Let's capture our sequence of steps in an algorithm to find the MLE of a parameter given an i.i.d. sample.
- Write the likelihood of the sample. The goal is to find the value of the parameter that maximizes this likelihood.
- To make the maximization easier, take the log of the likelihood function.
- To maximize the log likelihood with respect to the parameter, take its derivative with respect to the parameter.
- Set the derivative equal to 0 and solve; the solution is the MLE.
Let's implement this algorithm in another example.
MLE of $p$ Based on a Bernoulli $(p)$ Sample¶
Let $X_1, X_2, \ldots, X_n$ be an i.i.d. Bernoulli $(p)$ sample. Our goal is to find the MLE of $p$.
The random variables are discrete, so the likelihood function is defined as the joint probability mass function evaluated at the sample. To see what this means, let's start with the example.
Suppose $n=5$ and the observed sequence of 1's and 0's is 01101. The likelihood function at $p$ is the chance of observing this sequence under that value of $p$:
$$ Lik(p) ~ = ~ (1-p)\cdot p \cdot p \cdot (1-p) \cdot p ~ = ~ p^3(1-p)^2 $$The likelihood depends on the number of 1's, just as in the binomial probability formula. The combinatorial term is missing because we are observing each element of the sequence.
Now let's implement our algorithm for finding the MLE.
Step 1: Find the likelihood function.
Let $X = X_1 + X_2 + \ldots + X_n$ be the number of 1's in the sample. The likelihood function is
$$ Lik(p) = p^X (1-p)^{n-X} $$Step 2. Find the log likelihood function.
$$ L(p) = X\log(p) + (n-X)\log(1-p) $$Step 3. Find the derivative of the log likelihood function.
$$ \frac{d}{dp} L(p) = \frac{X}{p} - \frac{n-X}{1-p} $$Step 4. Set equal to 0 and solve for the MLE.
$$ \frac{X}{\hat{p}} - \frac{n-X}{1-\hat{p}} = 0 $$Hence $$ (1-\hat{p})X = (n-X)\hat{p} ~~~~~ \text{so} ~~~~~ X = n\hat{p} $$
Therefore the MLE of $p$ is $$ \hat{p} = \frac{X}{n} = \frac{1}{n}\sum_{i=1}^n X_i $$
That is, the MLE of $p$ is the sample proportion of 1's. To compute this estimate, all you need is the number of 1's in the sample. You don't need to see the entire sample as a sequence of 0's and 1's.
Because the MLE $\hat{p}$ is the sample proportion, it is unbiased, has SD $\sqrt{p(1-p)/n}$, and is asymptotically normal. When $n$ is large you can estimate the SD based on the sample and therefore construct confidence intervals for $p$.
Properties of the MLE¶
In the two examples above, the MLE is unbiased and either exactly normal or asymptotically normal. In general, MLEs need not be unbiased, as you will see in an example below. However, under some regularity conditions on the underlying probability distribution or mass function, when the sample is large the MLE is:
- consistent, that is, likely to be close to the parameter
- roughly normal and almost unbiased
Establishing this is outside the scope of this class, but in exercises you will observe these properties through simulation.
Though there is beautiful theory about the asymptotic variance of the MLE, in practice it can be hard to estimate the variance analytically. This can make it hard to find formulas for confidence intervals. However, you can use the bootstrap to estimate the variance: each bootstrapped sample yields a value of the MLE, and you can construct confidence intervals based on the empirical distribution of the bootstrapped MLEs.
MLEs of $\mu$ and $\sigma$ Based on a Normal $(\mu, \sigma^2)$ Sample¶
Let $X_1, X_2, \ldots, X_n$ be an i.i.d. normal $(\mu, \sigma^2)$ sample. We will now find the MLEs of both $\mu$ and $\sigma$.
The Likelihood Function¶
We have to think of this as a function of both $\mu$ and $\sigma$:
$$ Lik(\mu, \sigma) ~ = ~ \prod_{i=1}^n \frac{1}{\sqrt{2\pi}\sigma} \exp \big{(} -\frac{1}{2} \big{(} \frac{X_i - \mu}{\sigma} \big{)}^2 \big{)} ~ = ~ C \cdot \frac{1}{\sigma^n} \prod_{i=1}^n \exp \big{(} -\frac{1}{2\sigma^2} (X_i - \mu)^2 \big{)} $$where $C = 1/(\sqrt{2\pi})^n$ does not affect the maximization.
The Log Likelihood Function¶
$$ L(\mu, \sigma) ~ = ~ \log(C) - n\log(\sigma) - \frac{1}{2\sigma^2}\sum_{i=1}^n (X_i - \mu)^2 $$Maximizing the Log Likelihood Function¶
We will maximize $L$ in two stages:
- First fix $\sigma$ and maximize with respect to $\mu$.
- Then plug in the maximizing value of $\mu$ and maximize the resulting function with respect to $\sigma$.
We have already completed the first stage in the first example of this section. For each fixed $\sigma$, the maximizing value of $\mu$ is $\hat{\mu} = \bar{X}$.
So now our job is to find the value $\hat{\sigma}$ that maximizes the new function
$$ L^*(\sigma) ~ = ~ -n\log(\sigma) - \frac{1}{2\sigma^2}\sum_{i=1}^n (X_i - \bar{X})^2 ~ = ~ -n\log(\sigma) - \frac{1}{2\sigma^2} V $$where $V = \sum_{i=1}^n (X_i - \bar{X})^2$ doesn't depend on $\sigma$. Differentiate with respect to $\sigma$; keep track of minus signs and factors of 2.
$$ \frac{d}{d\sigma} L^*(\sigma) ~ = ~ -\frac{n}{\sigma} + \frac{1}{\sigma^3}V $$Set this equal to 0 and solve for the maximizing value $\hat{\sigma}$.
$$ -\frac{n}{\hat{\sigma}} + \frac{1}{\hat{\sigma}^3}V ~ = ~ 0 ~~~~~~~ \Longleftrightarrow ~~~~~~~ \hat{\sigma}^2 ~ = ~ \frac{V}{n} ~ = ~ \frac{1}{n} \sum_{i=1}^n (X_i - \bar{X})^2 $$Again you should check that this yields a maximum and not a minimum, but again given the answer you will surely accept that it's a max.
You have shown in exercises that $\hat{\sigma}^2$ is not an unbiased estimate of $\sigma^2$. You have also shown that it is close to unbiased when $n$ is large.
To summarize our result, if $X_1, X_2, \ldots , X_n$ is an i.i.d. normal $(\mu, \sigma^2)$ sample, then the MLEs of $\mu$ and $\sigma$ are given by:
- $\hat{\mu} = \bar{X}$
- $\hat{\sigma} = \sqrt{\hat{\sigma}^2}$ where $\hat{\sigma}^2 = \frac{1}{n} \sum_{i=1}^n (X_i - \bar{X})^2$
It is a remarkable fact about i.i.d. normal samples that $\hat{\mu}$ and $\hat{\sigma}^2$ are independent of each other even though they are statistics calculated from the same sample. Towards the end of this course you will see why.
Computational Note: MLEs can't always be derived analytically as easily as in our examples. It's important to keep in mind that maximizing log likelihood functions can often be intractable without a numerical optimization method. Also, not all likelihood functions have unique maxima.