Chain at a Fixed Time
The Chain at a Fixed Time¶
Let $X_0, X_1, X_2, \ldots $ be a Markov Chain with state space $S$. We will start by setting up notation that will help us express our calculations compactly.
For $n \ge 0$, let $P_n$ be the distribution of $X_n$. That is,
$$ P_n(i) = P(X_n = i), ~~~~ i \in S $$Then the distribution of $X_0$ is $P_0$. This is called the initial distribution of the chain.
For $n \ge 0$ and $j \in S$,
\begin{align*} P_{n+1}(j) &= P(X_{n+1} = j) \\ &= \sum_{i \in S} P(X_n = i, X_{n+1} = j) \\ &= \sum_{i \in S} P(X_n = i)P(X_{n+1} = j \mid X_n = i) \\ &= \sum_{i \in S} P_n(i)P(X_{n+1} = j \mid X_n = i) \end{align*}The conditional probability $P(X_{n+1} = j \mid X_n = i)$ is called a one-step transition probability at time $n$.
For many chains such as the random walk, these one-step transition probabilities depend only on the states $i$ and $j$, not on the time $n$. For example, for the random walk,
\begin{equation} P(X_{n+1} = j \mid X_n = i) = \begin{cases} \frac{1}{2} & \text{if } j = i-1 \text{ or } j = i+1 \\ 0 & \text{ otherwise} \end{cases} \end{equation}for every $n$. When one-step transition probabilites don't depend on $n$, they are called stationary or time-homogenous. All the Markov Chains that we will study in this course have time-homogenous transition probabilities.
For such a chain, define the one-step transition probability
$$ P(i, j) = P(X_{n+1} = j \mid X_n = i) $$The Probability of a Path¶
Given that the chain starts at $i$, what is the chance that the next three values are of the chain are $j, k$, and $l$, in that order?
We are looking for $$ P(X_1 = j, X_2 = k, X_3 = l \mid X_0 = i) $$
By repeated use of the multiplication rule and the Markov property, this is
$$ P(X_1 = j, X_2 = k, X_3 = l \mid X_0 = i) = P(i, j)P(j, k)P(k, l) $$In the same way, given that you know the starting point, you can find the probability of any path of finite length by multiplying one-step transition probabilities.
The Distribution of $X_{n+1}$¶
By our calculation at the start of this section,
\begin{align*} P_{n+1}(j) &= P(X_{n+1} = j) \\ &= \sum_{i \in S} P_n(i)P(X_{n+1} = j \mid X_n = i) \\ &= \sum_{i \in S} P_n(i)P(i, j) \end{align*}The calculation is based on the straightforward observation that for the chain to be at state $j$ at time $n+1$, it had to be at some state $i$ at time $n$ and then get from $i$ to $j$ in one step.
Let's use all this in examples. You will quickly see that the distribution $P_n$ has interesting properties.
Lazy Random Walk on a Circle¶
Let the state space be five points arranged on a circle. Suppose the process starts at Point 1, and at each step either stays in place with probability 0.5 (and thus is lazy), or moves to one of the two neighboring points with chance 0.25 each, regardless of the other moves.
This transition behavior can be summed up in a transition diagram:
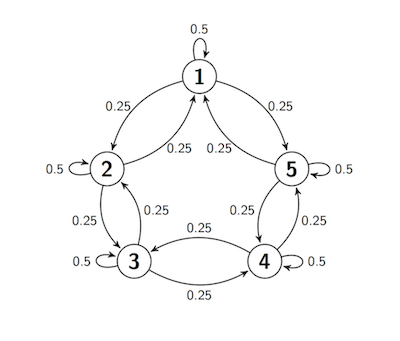
At every step, the next move is determined by a random choice from among three options and by the chain's current location, not on how it got to that location. So the process is a Markov chain. Let's call it $X_0, X_1, X_2, \ldots $.
By our assumption, the initial distribution $P_0$ puts all the probability on Point 1. It is defined in the cell below. We will be using prob140 Markov Chain methods based on Pykov written by Riccardo Scalco. Note the use of states instead of values. Please enter the states in ascending order, for technical reasons that we hope to overcome later in the term.
s = np.arange(1, 6)
p = [1, 0, 0, 0, 0]
initial = Table().states(s).probability(p)
initial
The transition probabilities are:
- For $2 \le i \le 4$, $P(i, i) = 0.5$ and $P(i, i-1) = 0.25 = P(i, i+1)$.
- $P(1, 1) = 0.5$ and $P(1, 5) = 0.25 = P(1, 2)$.
- $P(5, 5) = 0.5$ and $P(5, 4) = 0.25 = P(5, 1)$.
These probabilities are returned by the function circle_walk_probs that takes states $i$ and $j$ as its arguments.
def circle_walk_probs(i, j):
if i-j == 0:
return 0.5
elif abs(i-j) == 1:
return 0.25
elif abs(i-j) == 4:
return 0.25
else:
return 0
All the transition probabilities can be captured in a table, in a process analogous to creating a joint distribution table.
trans_tbl = Table().states(s).transition_function(circle_walk_probs)
trans_tbl
Just as when we were constructing joint distribution tables, we can better visualize this as a $5 \times 5$ table:
circle_walk = trans_tbl.toMarkovChain()
circle_walk
This is called the transition matrix of the chain.
- For each $i$ and $j$, the $(i, j)$ element of the transition matrix is the one-step transition probability $P(i, j)$.
- For each $i$, the $i$th row of the transition matrix consists of the conditional distribution of $X_{n+1}$ given $X_n = i$.
Probability of a Path¶
What's the probability of the path 1, 1, 2, 1, 2? That's the path $X_0 = 1, X_1 = 1, X_2 = 2, X_3 = 1, X_4 = 2$. We know that the chain is starting at 1, so the chance of the path is
$$ 1 \cdot P(1, 1)P(1, 2)P(2, 1)P(1, 2) = 0.5 \times 0.25 \times 0.25 \times 0.25 = 0.0078125 $$The method prob_of_path takes the initial distribution and path as its arguments, and returns the probability of the path:
circle_walk.prob_of_path(initial, [1, 1, 2, 1, 2])
Distribution of $X_n$¶
Remember that the chain starts at 1. So $P_0$, the distribution of $X_0$ is:
initial
We know that $P_1$ must place probability 0.5 at Point 1 and 0.25 each the points 2 and 5. This is confirmed by the distribution method that applies to a MarkovChain object. Its first argument is the initial distribution, and its second is the number of steps $n$. It returns a distribution object that is the distribution of $X_n$.
P_1 = circle_walk.distribution(initial, 1)
P_1
What's the probability that the chain is has value 3 at time 2? That's $P_2(3)$ which we can calculate by conditioning on $X_1$:
$$ P_2(3) = \sum_{i=1}^5 P_1(i)P(i, 3) $$The distribution of $X_1$ is $P_1$, given above. Here are those probabilities in an array:
P_1.column('Probability')
The 3 column of the transition matrix gives us, for each $i$, the chance of getting from $i$ to 3 in one step.
circle_walk.column('3')
So the probability that the chain has the value 3 at time 2 is $P_2(3)$ which is equal to:
sum(P_1.column('Probability')*circle_walk.column('3'))
Similarly, $P_2(2)$ is equal to:
sum(P_1.column('Probability')*circle_walk.column('2'))
And so on. The distribution method finds all these probabilities for us.
P_2 = circle_walk.distribution(initial, 2)
P_2
At time 3, the chain continues to be much more likely to be at 1, 2, or 5 compared to the other two states. That's because it started at Point 1 and is lazy.
P_3 = circle_walk.distribution(initial, 3)
P_3
But by time 10, something interesting starts to emerge.
P_10 = circle_walk.distribution(initial, 10)
P_10
The chain is almost equally likely to be at any of the five states. By time 50, it seems to have completely forgotten where it started, and is distributed uniformly on the state space.
P_50 = circle_walk.distribution(initial, 50)
P_50
As time passes, this chain gets "all mixed up", regardless of where it started. That is perhaps not surprising as the transition probabilities are symmetric over the five states. Let's see what happens when we cut the circle between Points 1 and 5 and lay it out in a line.
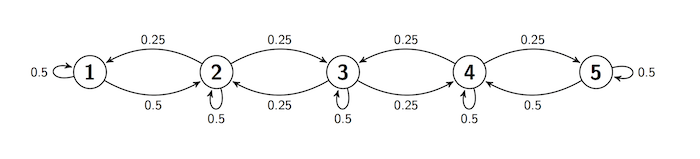
Reflecting Random Walk¶
The state space and transition probabilities remain the same, except when the chain is at the two "edge" states.
- If the chain is at Point 1, then at the next step it either stays there or moves to Point 2 with equal probability: $P(1, 1) = 0.5 = P(1, 2)$.
- If the chain is at Point 5, then at the next step it either stays there or moves to Point 4 with equal probability: $P(5, 5) = 0.5 = P(5, 4)$.
We say that there is reflection at the boundaries 1 and 5.
def ref_walk_probs(i, j):
if i-j == 0:
return 0.5
elif 2 <= i <= 4:
if abs(i-j) == 1:
return 0.25
else:
return 0
elif i == 1:
if j == 2:
return 0.5
else:
return 0
elif i == 5:
if j == 4:
return 0.5
else:
return 0
trans_tbl = Table().states(s).transition_function(ref_walk_probs)
refl_walk = trans_tbl.toMarkovChain()
print('Transition Matrix')
refl_walk
Let the chain start at Point 1 as it did in the last example. That initial distribution was defined as initial. At time 1, therefore, the chain is either at 1 or 2, and at times 2 and 3 it is likely to still be around 1.
refl_walk.distribution(initial, 1)
refl_walk.distribution(initial, 3)
But by time 20, the distribution is settling down:
refl_walk.distribution(initial, 20)
And by time 100 it has settled into what is called its steady state.
refl_walk.distribution(initial, 100)
This steady state distribution isn't uniform. But it is steady. If you increase the amount of time for which the chain has run, you get the same distribution for the value of the chain at that time.
That's quite remarkable. In the rest of this chapter, we will look more closely at what's going on.