6.1. The Binomial Distribution#
Let
Suppose you have a fixed number
the trials are independent; and
on each trial, the probability of success is
Let
The first goal of this section is to find the distribution of
In our earlier example, we were counting the number of sixes in 7 rolls of a die. The 7 rolls are independent of each other, the chance of “success” (getting a six) is
The first step in finding the distribution of any random variable is to identify the possible values of the variable. In
Thus the number of sixes in 7 rolls can be any integer in the 0 through 7 range. Let’s find
Partition the event
Now notice that
by independence. Indeed, any sequence of three S’s and four F’s has the same probability. So by the addition rule,
because
An analogous argument leads us to one of the most important distributions in probability theory.
6.1.1. The Binomial
Let
Parameters of a distribution are constants associated with it. The Bernoulli
See More
Before we get going on calculations with the binomial distribution, let’s make a few observations.
The functional form of the probabilities is symmetric in successes and failures, because
That’s “number of trials factorial; divided by number of successes factorial times number of failures factorial; times the probability of success to the power number of successes; times the probability of failure to the power number of failures.”
The formula makes sense for the edge cases
after all the dust clears in the formula; the first two factors are both 1. You can check that
Remember that
The probabilities in the distribution sum to 1. To see this, recall that for any two numbers
by the binomial expansion of
Plug in
6.1.2. Applying the Formula#
To use the binomial formula, you first have to recognize that it can be used, and then use it as you would use any distribution.
Check the conditions: a known number of independent, repeated, success/failure trials, and you are counting the number of successes
Identify the two parameters
Identify each
Add up the binomial
Quick Check
Every time I throw a dart, I have chance 25% of hitting the bullseye, independent of all other throws. Suppose I throw the dart 10 times. Find the chance that
(a) I hit the bullseye two times
(b) I hit the bullseye more than two times
(c) I hit the bullseye more than six times
Answer
(a)
(b)
(c)
6.1.3. Binomial Probabilities in Python#
SciPy is a system for scientific computing, based on Python. The stats submodule of scipy does numerous calculations in probability and statistics. We will be importing it at the start of every notebook from now on.
from scipy import stats
The function stats.binom.pmf takes three arguments:
The acronym “pmf” stands for probability mass function which as we have noted earlier is sometimes used as another name for the distribution of a variable that has finitely many values.
The chance of 3 sixes in 7 rolls of a die is
stats.binom.pmf(3, 7, 1/6)
0.078142861225423008
You can also specify an array or list of values of stats.binom.pmf will return an array consisting of all their probabilities.
stats.binom.pmf([2, 3, 4], 7, 1/6)
array([ 0.23442858, 0.07814286, 0.01562857])
Thus to find
sum(stats.binom.pmf([2, 3, 4], 7, 1/6))
0.32820001714677643
See More
6.1.4. Cumulative Distribution Function (cdf)#
To visualize binomial distributions we will use the prob140 method Plot, by first using stats.binom.pmf to calculate the binomial probabilities. The cell below plots the distribution of k.
n = 7
p = 1/6
k = np.arange(n+1)
binom_7_1_6 = stats.binom.pmf(k, n, p)
binom_7_1_6_dist = Table().values(k).probabilities(binom_7_1_6)
Plot(binom_7_1_6_dist)
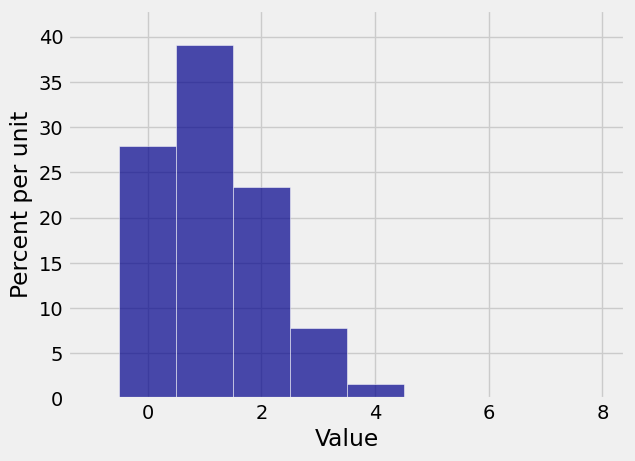
Very often, we need probabilities of the form
Plot(binom_7_1_6_dist, event=np.arange(0, 3))
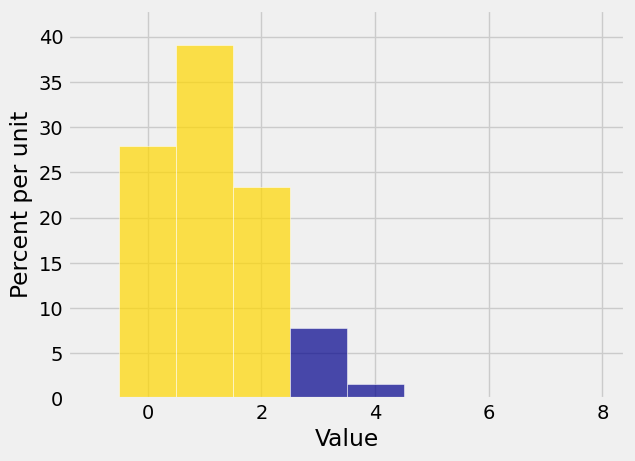
The cumulative distribution function or c.d.f. of any random variable is a function that calculates this “area to the left” of any point. If you denote the c.d.f. by
for any x.
We will get to know this function better later in the course. For now, note that stats lets you calculate it directly without having to use pmf and then summing. The function is called stats.distribution_name.cdf where distribution_name could be binom or hypergeom or any other distribution name that stats recognizes. The first argument is
For
To find
1 - stats.binom.cdf(2, 7, 1/6)
0.095775462962963021
stats.binom.cdf(2, 7, 1/6)
0.90422453703703698
Here is the event
k = np.arange(21)
probs = stats.binom.pmf(k, 20, 0.4)
binom_20_point4 = Table().values(k).probabilities(probs)
Plot(binom_20_point4, event=np.arange(6, 11))
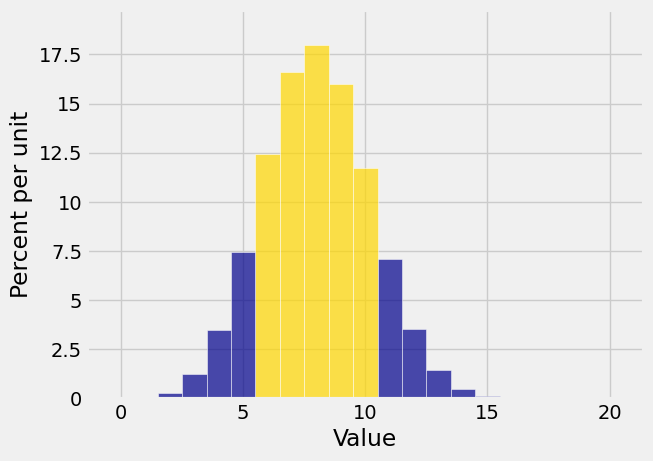
To find
That’s about 74.7%.
stats.binom.cdf(10, 20, 0.4) - stats.binom.cdf(5, 20, 0.4)
0.74687978112974585
6.1.5. Binomial Histograms#
Here is the histogram of the binomial
Plot(binom_7_1_6_dist)
This distribution is not symmetric, as you would expect. But something interesting happens to the distribution of the number of sixes when you increase the number of rolls.
n = 600
p = 1/6
k = np.arange(n+1)
binom_600_1_6 = stats.binom.pmf(k, n, p)
binom_600_1_6_dist = Table().values(k).probabilities(binom_600_1_6)
Plot(binom_600_1_6_dist)
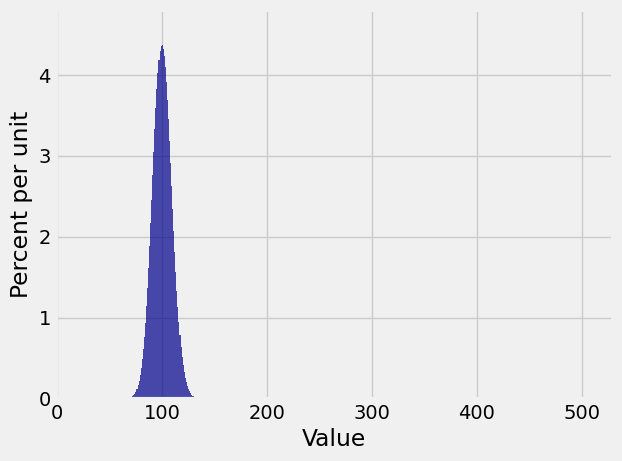
This distribution is close to symmetric, even though the die has only a 1/6 chance of showing a six.
Also notice that while the the possible values of the number of sixes range from 0 to 600, the probable values are in a much smaller range. The plt.xlim function allows us to zoom in on the probable values. The semicolon is just to prevent Python giving us a message that clutters up the graph. The edges=True option forces Plot to draw lines separating the bars; by default, it stops doing that if the number of bars is large.
Plot(binom_600_1_6_dist, edges=True)
plt.xlim(70, 130);
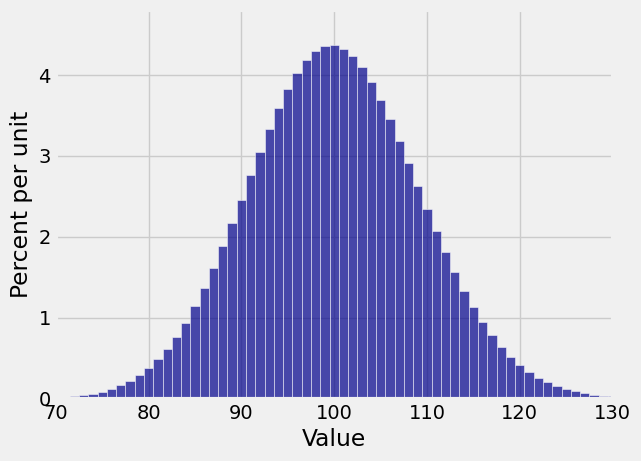
But the binomial
Something quite different happens if for example your random variable is the number of successes in 600 independent trials that have probability 1/600 of success on each trial. Then the distribution of the number of successes is binomial
n = 600
p = 1/600
k = np.arange(n+1)
binom_600_1_600 = stats.binom.pmf(k, n, p)
binom_600_1_600_dist = Table().values(k).probabilities(binom_600_1_600)
Plot(binom_600_1_600_dist)
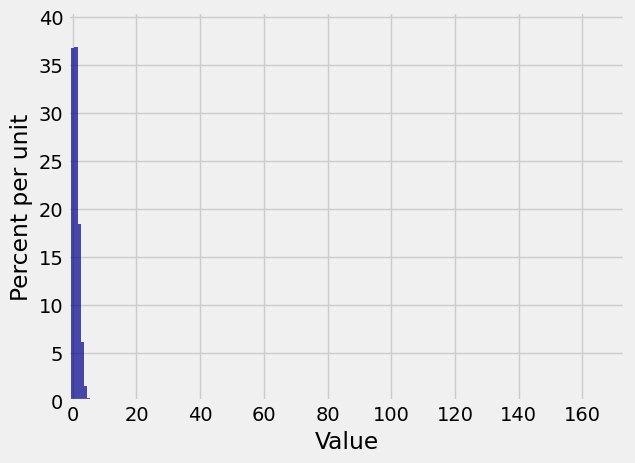
We really can’t see that at all! Let’s zoom in. When we set the limits on the horizontal axis, we have to account for the bar at 0 being centered at the 0 and hence starting at -0.5.
Plot(binom_600_1_600_dist, edges=True)
plt.xlim(-1, 10);
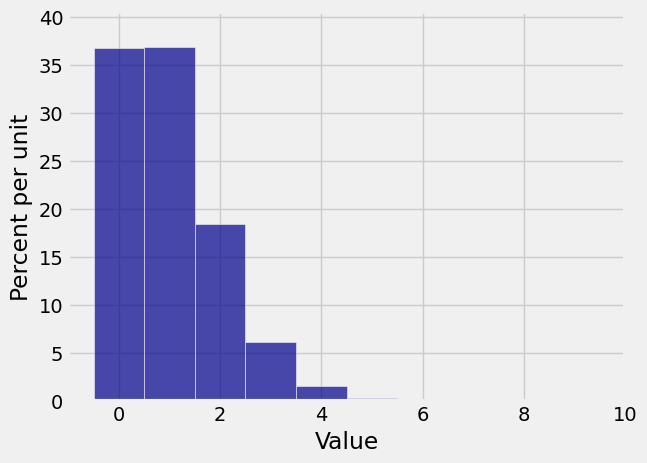
Now you can see that in 600 independent trials with probability 1/600 of success on each trial, you are most likely to get no successes or 1 success. There is some chance that you get 2 through 4 successes, but the chance of any number of successes greater than 4 is barely visible on the scale of the graph.
Clearly, the shape of the histogram is determined by both