18.2. Sums of Independent Normal Variables#
This section consists of examples based on one important fact:
The sum of independent normal variables is normal.
We will prove the fact in a later section using moment generating functions. For now, we will just run a quick simulation and then see how to use the fact in examples.
mu_X = 10
sigma_X = 2
mu_Y = 15
sigma_Y = 3
x = stats.norm.rvs(mu_X, sigma_X, size=10000)
y = stats.norm.rvs(mu_Y, sigma_Y, size=10000)
s = x+y
Table().with_column('S = X+Y', s).hist(bins=20)
plt.title('$X$ is normal (10, $2^2$); $Y$ is normal (15, $3^2$) independent of $X$');
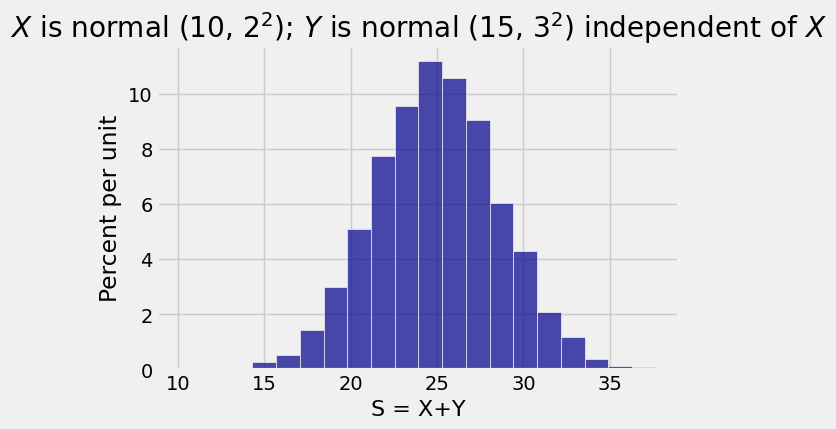
The simulation above generates 10,000 copies of
To identify which normal, you have to find the mean and variance of the sum. Just use properties of the mean and variance:
If
This means that we don’t need the joint density of
18.2.1. Sums of IID Normal Variables#
Let
This looks rather like the Central Limit Theorem but notice that there is no assumption that
If the underlying distribution is normal, then the distribution of the i.i.d. sample sum is normal regardless of the sample size.
18.2.2. The Difference of Two Independent Normal Variables#
If
For example, let the heights of Persons A and B be
because
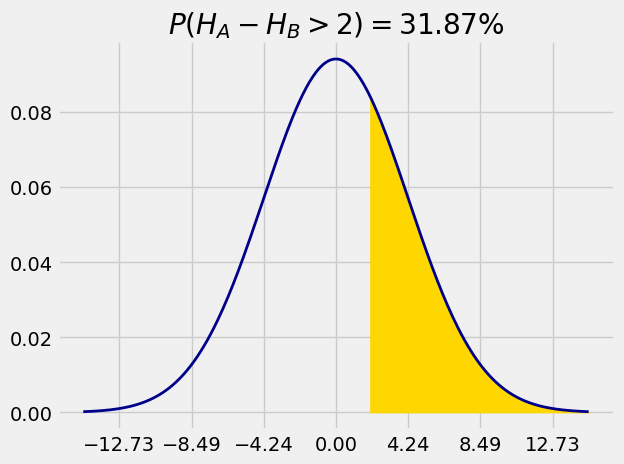
mu = 0
sigma = 18**0.5
1 - stats.norm.cdf(2, mu, sigma)
0.31867594411696853
18.2.3. Comparing Two Sample Proportions#
A candidate is up for election. In State 1, 50% of the voters favor the candidate. In State 2, only 27% of the voters favor the candidate. A simple random sample of 1000 voters is taken in each state. You can assume that the samples are independent of each other and that there are millions of voters in each state.
Question. Approximately what is the chance that in the sample from State 1, the proportion of voters who favor the candidate is more than twice as large as the proportion in the State 2 sample?
Answer. For
Now it’s just a matter of figuring out the mean and the SD.
So
mu = 0.5 - 2*0.27
var = (0.5*0.5/1000) + 4*(0.27*.73/1000)
sigma = var**0.5
1 - stats.norm.cdf(0, mu, sigma)
0.1072469993885582
Quick Check
Sketch the density of
Answer
Normal curve centered at 35, points of inflection at 35