12.1. Definition#
Define the deviation from the mean to be
For every random variable, the expected deviation from the mean is 0. The positive deviations exactly cancel out the negative ones.
This cancellation prevents us from understanding how big the deviations are regardless of their sign. But that’s what we need to measure, if we want to measure the distance between the random variable
We have to get rid of the sign of the deviation somehow. One time-honored way of getting rid of the sign of a number is to take the absolute value. The other is to square the number. That’s the method we will use. As you will see, it results in a measure of spread that is crucial for understanding the sums and averages of large samples.
Measuring the rough size of the squared deviations has the advantage that it avoids cancellation between positive and negative errors. The disadvantage is that squared deviations have units that are difficult to understand. The measure of spread that we are about to define takes care of this problem.
See More
12.1.1. Standard Deviation#
Let
The quantity inside the square root is called the variance of
Almost invariably, we will calculate standard deviations by first finding the variance and then taking the square root.
Let’s try out the definition of the SD on a random variable
x = make_array(3, 4, 5)
probs = make_array(0.2, 0.5, 0.3)
dist_X = Table().values(x).probability(probs)
dist_X
| Value | Probability |
|---|---|
| 3 | 0.2 |
| 4 | 0.5 |
| 5 | 0.3 |
dist_X.ev()
4.0999999999999996
Here are the squared deviations from the expectation
sd_table = Table().with_columns(
'x', dist_X.column(0),
'(x - 4.1)**2', (dist_X.column(0)-4.1)**2,
'P(X = x)', dist_X.column(1)
)
sd_table
| x | (x - 4.1)**2 | P(X = x) |
|---|---|---|
| 3 | 1.21 | 0.2 |
| 4 | 0.01 | 0.5 |
| 5 | 0.81 | 0.3 |
The standard deviation of
sd_X = np.sqrt(sum(sd_table.column(1)*sd_table.column(2)))
sd_X
0.69999999999999996
The prob140 method sd applied to a distribution object returns the standard deviation, saving you the calculation above.
dist_X.sd()
0.7
Quick Check
The random variable
(a) Find
(b) Apply the definition of standard deviation to find
Answer
(a)
(b)
We now know how to calculate the SD. But we don’t yet have a good understanding of what it does. Let’s start developing a few properties that it ought to have. Then we can check if it has them.
First, the SD of a constant should be 0. You should check that this is indeed what the definition implies.
12.1.2. Shifting and Scaling#
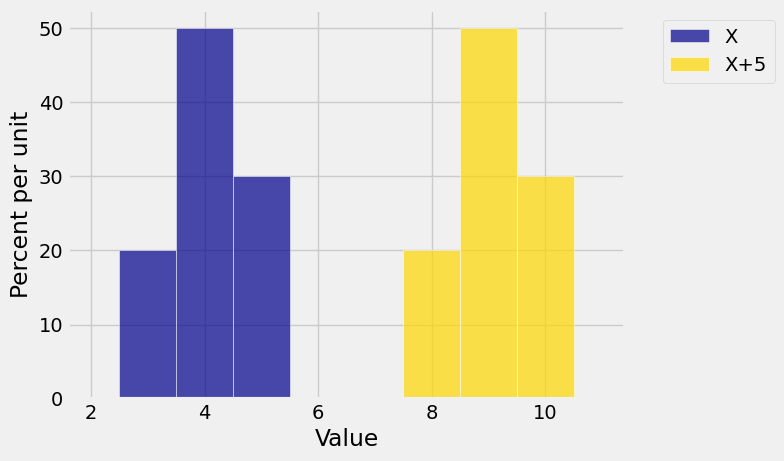
The SD is a measure of spread. It’s natural to want measures of spread to remain unchanged if we just shift a probability histogram to the left or right. Such a shift occurs when we add a constant to a random variable. The figure below shows the distribution of the same
dist2 = Table().values(x+5).probability(probs)
Plots('X', dist_X, 'X+5', dist2)
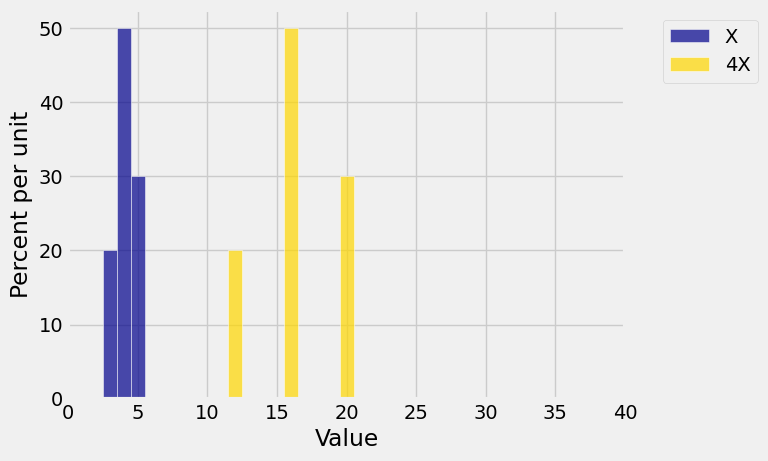
On the other hand, multiplying
dist3 = Table().values(4*x).probability(probs)
Plots('X', dist_X, '4X', dist3 )
plt.xlim(0, 40);
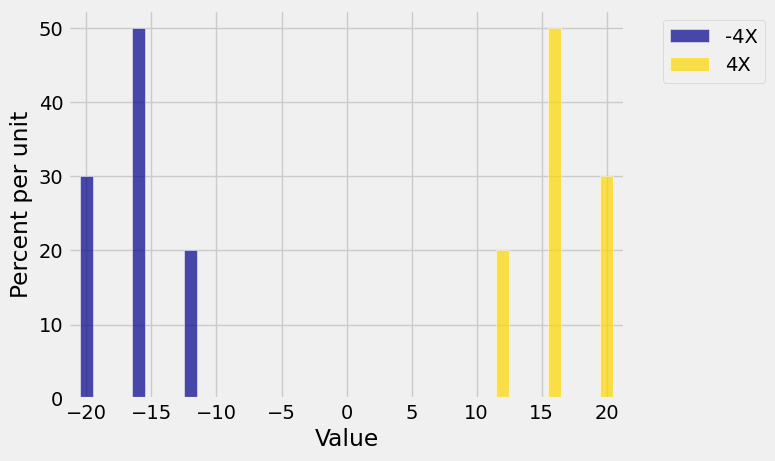
Multiplying by
dist4 = Table().values(-4*x).probability(probs)
Plots('-4X', dist4, '4X', dist3 )
See More
12.1.3. Linear Functions#
The graphs above help us visualize what happens to the SD when the random variable is transformed linearly, for example when changing units of measurement. Let
Notice that the shift
Because the units of the variance are the square of the units of
Notice that you get the same answer when the multiplicative constant is
In particular, it is very handy to remember that
Quick Check
Let
Answer
12.1.4. “Computational” Formula for Variance#
An algebraic simplification of the formula for variance turns out to be very useful.
Thus the variance is the “mean of the square minus the square of the mean.”
Apart from giving us an alternative way of calculating variance, the formula tells us something about the relation between
with equality only when
The formula is often called the “computational” formula for variance. But it can be be numerically inaccurate if the possible values of
Quick Check
Return to the random variable
Answer
See More
12.1.5. Indicator#
The values of an indicator random variable are 0 and 1. Each of those two numbers is equal to its square. So if
You should check that this variance is largest when
12.1.6. Uniform#
Let
In the last-but-one step above, we used the formula for the sum of the first
We know that
and
By shifting, this is the same as the SD of the uniform distribution on any
12.1.7. Poisson#
Let
We also know that
and
So for example if