12.2. Prediction and Estimation#
One way to think about the SD is in terms of errors in prediction. Suppose I am going to generate a value of the random variable
A natural choice is
Notice that by definition, the variance of
See More
We will now show that
with equality if and only if
12.2.1. The Mean as a Least Squares Predictor#
What we have shown is the predictor
This is why a common approach to prediction is, “My guess is the mean, and I’ll be off by about an SD.”
Quick Check
Your friend has a random dollar amount
(a) What is the least squares constant predictor of
(b) What is the mean squared error of this predictor?
(c) What is the root mean squared error of this predictor?
Answer
(a)
(b)
(c)
12.2.2. German Tanks, Revisited#
Recall the German tanks problem in which we have a sample
We came up with two unbiased estimators of
An estimator based on the sample mean:
An estimator based on the sample maximum:
Here are simulated distributions of
def simulate_T1_T2(N, n):
"""Returns one pair of simulated values of T_1 and T_2
based on the same simple random sample"""
tanks = np.arange(1, N+1)
sample = np.random.choice(tanks, size=n, replace=False)
t1 = 2*np.mean(sample) - 1
t2 = max(sample)*(n+1)/n - 1
return [t1, t2]
def compare_T1_T2(N, n, repetitions):
"""Returns a table of simulated values of T_1 and T_2,
with the number of rows = repetitions
and each row containing the two estimates based on the same simple random sample"""
tbl = Table(['T_1 = 2*Mean-1', 'T_2 = Augmented Max'])
for i in range(repetitions):
tbl.append(simulate_T1_T2(N, n))
return tbl
N = 300
n = 30
repetitions = 5000
comparison = compare_T1_T2(N, n, 5000)
comparison.hist(bins=np.arange(N/2, 3*N/2))
plt.title('$N =$'+str(N)+', $n =$'+str(n)+' ('+str(repetitions)+' repetitions)');
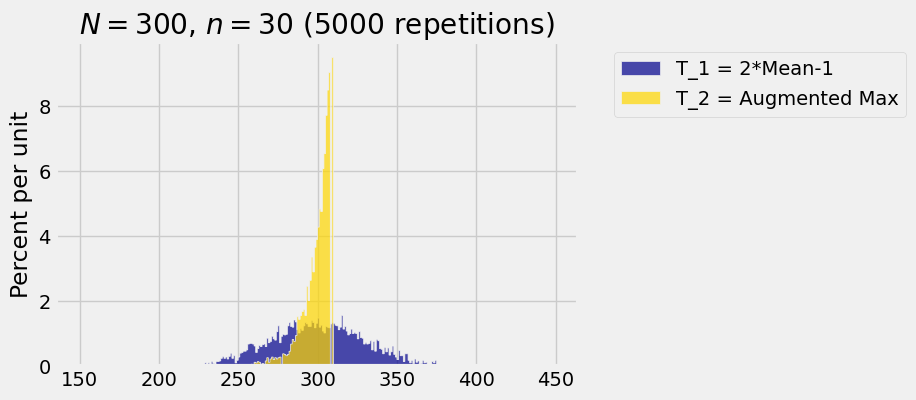
We know that both estimators are unbiased:
The empirical values of the two means and standard deviations based on this simulation are calculated below.
t1 = comparison.column(0)
np.mean(t1), np.std(t1)
(300.07926666666668, 30.068877736808055)
t2 = comparison.column(1)
np.mean(t2), np.std(t2)
(299.98106666666666, 9.1113762209668376)
These standard deviations are calculated based on empirical data given a specified value of the parameter