10.3. Long Run Behavior#
Every irreducible and aperiodic Markov Chain on a finite state space exhibits astonishing regularity after it has run for a while. The proof of the convergence theorem below is beyond the scope of this course, but in examples you have seen the result by computation. All the results are true in greater generality for some classes of Markov Chains on infinitely many states.
See More
10.3.1. Convergence to Stationarity#
Let
In other words, for every
That is, as
10.3.2. Properties of the Limit#
In this section we will establish the following results. All of them are useful for calculation and for understanding the long run behavior of Markov chains.
(i) The row vector
(ii) If for some
(iii) For each state
We will assume that the convergence theorem is true; you have observed in numerically in examples. The other properties follow rather easily. In the remainder of this section we will establish the properties and see how they are used.
See More
10.3.3. Balance Equations#
In our example of the sticky reflecting walk, we found the steady state distribution by computation: we simply computed the
But there is also a simple analytical way of finding the steady state distribution. To see this, let
Therefore
We can exchange the limit and the sum because
These are called the balance equations. There is one equation for each state
In matrix notation, if you think of
The balance equations help us compute
In a later chapter we will see how the term balance arises. For now, let’s focus on solving the equations.
10.3.4. Uniqueness#
It’s not very hard to show that if a probability distribution solves the balance equations, then it has to be
This is particularly helpful if you happen to guess a solution to the balance equations. If the solution that you have guessed is a probability distribution, you have found the stationary distribution of the chain.
10.3.5. Solving the Balance Equations#
The zero vector solves the balance equations, but it’s not a probability distribution.
To find non-zero solutions, it is tempting to rewrite the balance equations as
So there are multiple solutions of the balance equations. We can see this easily by noting that if any vector solves the balance equations, then 10 times that vector also solves them.
Our job is to find the solution that is also a probability distribution. That’s the steady state vector
Let
Two key observations help us solve the balance equations.
The equations say that for each state
There are therefore
In many examples, there is an efficient way of solving these equations.
Try to manipulate each balance equation so that you can write each
Then solve for that key element of
Here is an example of carrying out this process.
10.3.6. Stationary Distribution of Sticky Reflecting Walk#
We studied this in an earlier section. The transition diagram is
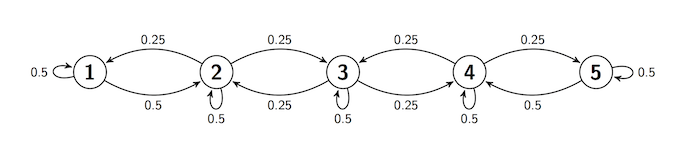
Here is the transition matrix
reflecting_walk
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | 0.50 | 0.50 | 0.00 | 0.00 | 0.00 |
| 2 | 0.25 | 0.50 | 0.25 | 0.00 | 0.00 |
| 3 | 0.00 | 0.25 | 0.50 | 0.25 | 0.00 |
| 4 | 0.00 | 0.00 | 0.25 | 0.50 | 0.25 |
| 5 | 0.00 | 0.00 | 0.00 | 0.50 | 0.50 |
The MarkovChain method steady_state returns the stationary distribution
reflecting_walk.steady_state()
| Value | Probability |
|---|---|
| 1 | 0.125 |
| 2 | 0.25 |
| 3 | 0.25 |
| 4 | 0.25 |
| 5 | 0.125 |
We could also solve for
According to the balance equations,
Rearrange this to write
Follow the same process with the next equation.
Rearrange this and plug in
Similarly, you will get
So
Now use the fact that
See More
10.3.7. Steady State#
The steady state isn’t an element of the state space
The theorem on convergence to stationarity says that the chain approaches the steady state as
by the balance equations. Now use induction.
In particular, if you start the chain with its stationary distribution
10.3.8. Expected Long Run Proportion of Time#
Suppose you run a chain for a long time. Then the chance that the chain is at state
Formally, let
Therefore, the expected proportion of time the chain spends at
Now recall a property of convergent sequences of real numbers:
If
Take
and hence the averages also converge:
Thus the long run expected proportion of time the chain spends in state
10.3.9. Sticky Random Walk on a Circle#
Now let the state space be five points arranged on a circle. Suppose the process starts at Point 1, and at each step either stays in place with probability 0.5 (and thus is sticky), or moves to one of the two neighboring points with chance 0.25 each, regardless of the other moves.
In other words, this walk is just the same as the sticky reflecting walk, except that
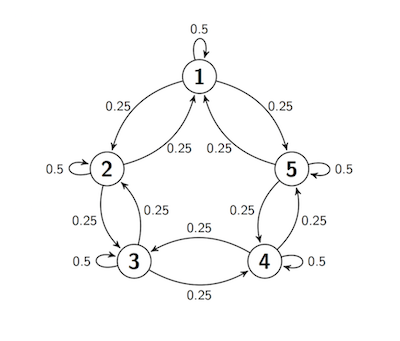
At every step, the next move is determined by a random choice from among three options and by the chain’s current location, not on how it got to that location. So the process is a Markov chain. Let’s call it
s = np.arange(1, 6)
def circle_walk_probs(i, j):
if i-j == 0:
return 0.5
elif abs(i-j) == 1:
return 0.25
elif abs(i-j) == 4:
return 0.25
else:
return 0
circle_walk = MarkovChain.from_transition_function(s, circle_walk_probs)
circle_walk
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | 0.50 | 0.25 | 0.00 | 0.00 | 0.25 |
| 2 | 0.25 | 0.50 | 0.25 | 0.00 | 0.00 |
| 3 | 0.00 | 0.25 | 0.50 | 0.25 | 0.00 |
| 4 | 0.00 | 0.00 | 0.25 | 0.50 | 0.25 |
| 5 | 0.25 | 0.00 | 0.00 | 0.25 | 0.50 |
Because of the symmetry of the transition behavior across all the states, in the long run no state should be occupied more than any other state. Hence all the steady_state, and you can also confirm it by checking that the vector
circle_walk.steady_state()
| Value | Probability |
|---|---|
| 1 | 0.2 |
| 2 | 0.2 |
| 3 | 0.2 |
| 4 | 0.2 |
| 5 | 0.2 |