14.6. Confidence Intervals#
Suppose you have a large i.i.d. sample
where
See More
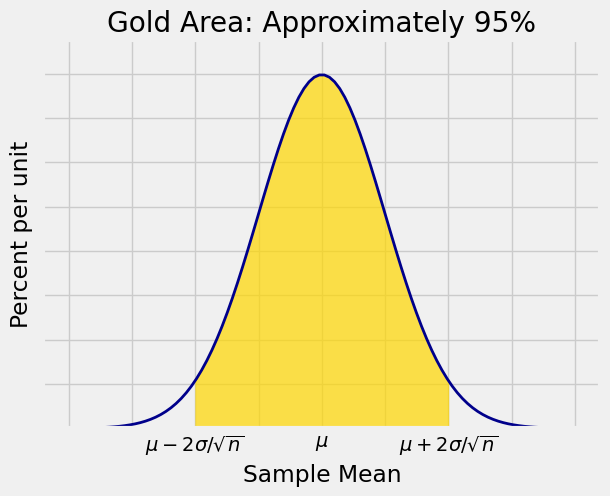
This can be expressed in a different way:
Distance is symmetric, so this is the same as saying:
That is why the interval “sample mean
The interval
Quick Check
True or false: Under the assumptions and notation used above, the interval
Answer
False
14.6.1. Changing the Confidence Level#
You could choose a different confidence level, say 80%. With that choice you would expect the interval to be narrower. To find out exactly how many SDs you have to go on either side of the center to pick up a central area of about 80%, you have to find the corresponding
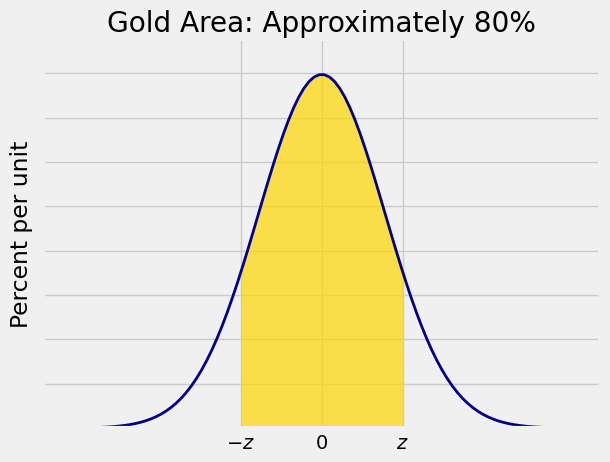
As you know from Data 8 and can see in the figure, the interval runs from the 10th percentile to the 90th percentile of the distribution. So
stats.norm.ppf(.9)
1.2815515655446004
Therefore an approximate 80% confidence interval for the population mean
Let’s double check that
stats.norm.ppf(.975)
1.959963984540054
That’s
See More
14.6.2. Confidence Interval for Population Mean#
Let
Let
because all of the area to the left of
If
The random interval
The only difference between confidence intervals of different levels is the choice of
14.6.3. A Data 8 Example Revisited#
Let’s return to an example very familiar from Data 8: a random sample of 1,174 pairs of mothers and their newborns.
baby = Table.read_table('baby.csv')
baby
| Birth Weight | Gestational Days | Maternal Age | Maternal Height | Maternal Pregnancy Weight | Maternal Smoker |
|---|---|---|---|---|---|
| 120 | 284 | 27 | 62 | 100 | False |
| 113 | 282 | 33 | 64 | 135 | False |
| 128 | 279 | 28 | 64 | 115 | True |
| 108 | 282 | 23 | 67 | 125 | True |
| 136 | 286 | 25 | 62 | 93 | False |
| 138 | 244 | 33 | 62 | 178 | False |
| 132 | 245 | 23 | 65 | 140 | False |
| 120 | 289 | 25 | 62 | 125 | False |
| 143 | 299 | 30 | 66 | 136 | True |
| 140 | 351 | 27 | 68 | 120 | False |
... (1164 rows omitted)
The third column consists of the ages of the mothers. Let’s construct an approximate 95% confidence interval for the mean age of mothers in the population. We did this in Data 8 using the bootstrap, so we will be able to compare results.
We can apply the methods of this section because our data come from a large random sample.
ages = baby.column('Maternal Age')
samp_mean = np.mean(ages)
samp_mean
27.228279386712096
n = baby.num_rows
n
1174
The observed value of
But of course we don’t know the population SD
As data scientists, we are used to lifting ourselves by our own bootstraps. Notice that the SD of the sample mean is
That means we can use “sample SD divided by
The sample SD, our estimate of
sigma_estimate = np.std(ages)
sigma_estimate
5.8153604041908968
An approximate 95% confidence interval for the mean weight of mothers in the population is
sd_sample_mean = sigma_estimate/(n ** 0.5)
ci_95_pop_mean = samp_mean + 1.96 * make_array(-1, 1) * sd_sample_mean
ci_95_pop_mean
array([ 26.89562086, 27.56093791])
No bootstrapping required!
See More
Now let’s compare our interval to the interval we got in Data 8 by using the bootstrap percentile method. Here is the function bootstrap_mean from Data 8.
def bootstrap_mean(original_sample, label, replications):
"""Displays approximate 95% confidence interval for population mean.
original_sample: table containing the original sample
label: label of column containing the variable
replications: number of bootstrap samples
"""
just_one_column = original_sample.select(label)
n = just_one_column.num_rows
means = make_array()
for i in np.arange(replications):
bootstrap_sample = just_one_column.sample()
resampled_mean = np.mean(bootstrap_sample.column(0))
means = np.append(means, resampled_mean)
left = percentile(2.5, means)
right = percentile(97.5, means)
resampled_means = Table().with_column(
'Bootstrap Sample Mean', means
)
resampled_means.hist(bins=15)
print('Approximate 95% confidence interval for population mean:')
print(np.round(left, 2), 'to', np.round(right, 2))
plt.plot(make_array(left, right), make_array(0, 0), color='yellow', lw=8);
Let’s construct a bootstrap 95% confidence interval for the population mean. We will use 5000 bootstrap samples as we did in Data 8.
bootstrap_mean(baby, 'Maternal Age', 5000)
Approximate 95% confidence interval for population mean:
26.9 to 27.56
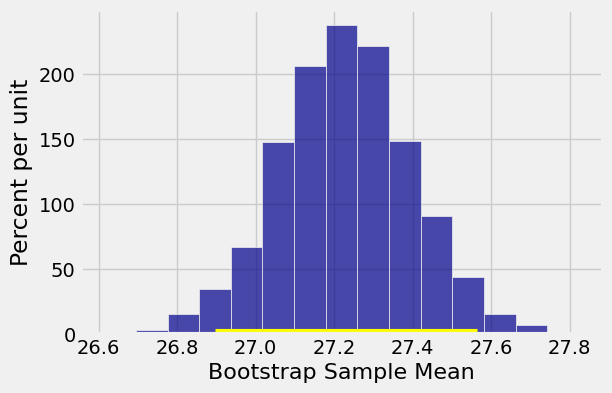
The bootstrap confidence interval is essentially identical to the interval (26.89, 27.57) that we got by using the normal approximation.
As we did in Data 8, let’s observe that the distribution of maternal ages in the sample is far from normal:
baby.select('Maternal Age').hist()
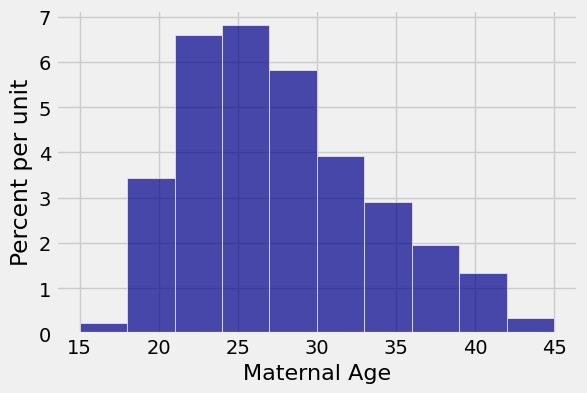
But the empirical distribution of the sample mean, displayed as the output of the previous cell, is roughly bell shaped. That is because the probability distribution of the mean of the large sample is approximately normal by the Central Limit Theorem, even though the distribution of the population is skewed.
Note on the bootstrap
Why did we use the bootstrap for creating confidence intervals in Data 8, if the intervals can be calculated as simply as in this section?
The reason is that the methods of this section apply only to confidence intervals for the population mean, based on large i.i.d. samples. If you want to estimate a population median instead, as we did in Data 8, then the simple method above doesn’t work. The calculation and estimation of the SD is harder. But the bootstrap takes care of that for us by using resampling to find the variability in our estimates. It allows us to construct confidence intervals in some situations where theoretical methods are intractable.
The bootstrap is a powerful process. However, if all we are doing is estimating a population mean, the methods of this section are simpler.