6.4. The Hypergeometric, Revisited#
You have seen the hypergeometric probabilities earlier. In this section we will use them to define the distribution of a random count, and study the relation with the binomial distribution.
As a review of the hypergeometric setting, suppose you have a population of a fixed size
a population of voters, and among them the group who will vote for a particular candidate
a population of households, and among them the group that have annual incomes below $50,000
a deck of cards, and the suit of diamonds
Let
Now suppose you take a simple random sample (SRS) of
6.4.1. Number of Good Elements in a SRS#
Let
The largest
Let
This is called the hypergeometric distribution with population size
6.4.2. Example: Aces in a Five-Card Poker Hand#
The number of aces
The stats.hypergeom.pmf function allows us to calculate hypergeometric probabilities. The first argument is the set of possible values for which we want the probabilities. Then come the parameters, in the order population size, number of good elements, sample size.
k = np.arange(5)
N = 52 # population size
G = 4 # number of good elements in population
n = 5 # simple random sample size
stats.hypergeom.pmf(k, N, G, n)
array([ 6.58841998e-01, 2.99473636e-01, 3.99298181e-02,
1.73607905e-03, 1.84689260e-05])
Those are the chances of all the different possible numbers of aces in a poker hand. They are rather hard to read, so let’s try rounding them.
np.round(stats.hypergeom.pmf(k, N, G, n), 3)
array([ 0.659, 0.299, 0.04 , 0.002, 0. ])
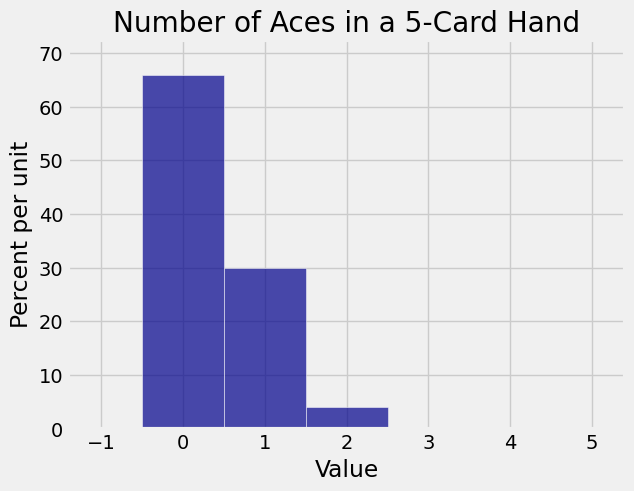
The number of aces among 5 cards is overwhelmingly likely to be 0 or 1. The histogram of the distribution can be drawn using Plot.
ace_probs = stats.hypergeom.pmf(k, N, G, n)
ace_dist = Table().values(k).probabilities(ace_probs)
Plot(ace_dist)
plt.title('Number of Aces in a 5-Card Hand');
6.4.3. Red Cards in a Bridge Hand#
Here is the distribution of the number of red cards in a bridge hand of 13 cards:
k = np.arange(14)
N = 52
G = 26
n = 13
bridge_probs = stats.hypergeom.pmf(k, N, G, n)
bridge_dist = Table().values(k).probabilities(bridge_probs)
Plot(bridge_dist)
plt.title('Number of Red Cards in a 13-Card Hand');
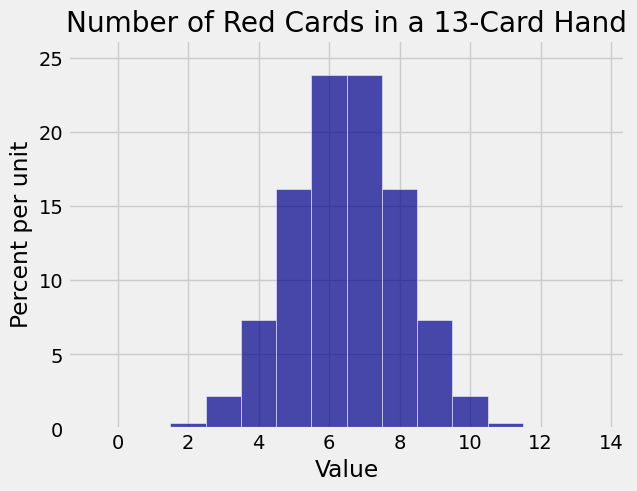
This one looks rather binomial. And indeed, there is a close relation between the binomial and the hypergeometric distributions.
6.4.4. Relation with the Binomial#
Suppose you have a population of
If you sample without replacement, then the distribution of the number of good elements is hypergeometric
The only difference between the two settings is the randomization: sampling with or without replacement.
If the population size
To see whether this intuition can be confirmed by calculation, let’s visualize some hypergeometric distributions and the corresponding binomial approximations. You can change the parameters in the code below. Just make sure that
N = 100
G = 30
n = 10
k = np.arange(n+1)
hyp_probs = stats.hypergeom.pmf(k, N, G, n)
bin_probs = stats.binom.pmf(k, n, G/N)
hyp_dist = Table().values(k).probabilities(hyp_probs)
bin_dist = Table().values(k).probabilities(bin_probs)
Plots('Hypergeometric (100, 30, 10)', hyp_dist, 'Binomial (10, 0.3)', bin_dist)
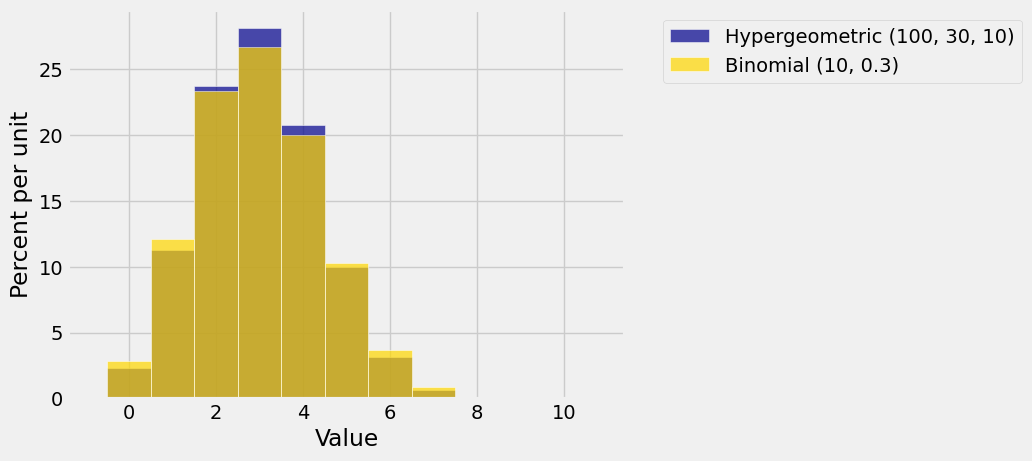
They are pretty close, though you can see that the hypergeometric distribution is a bit taller and narrower. In a later chapter we will quantify this difference in spread.
6.4.5. Fisher’s Exact Test#
Recall a randomized controlled experiment that was analyzed in Data 8. The treatment was the botulinum toxin A, a very potent toxin, used as medication for patients who had chronic back pain.
A total of 31 patients participated in the study. Of these, 15 were randomly assigned to the treatment group and the remaining 16 to the control group. Eight weeks after treatment, 11 of the 15 in the treatment group had pain relief compared to 2 out of 16 in the control group.
In other words, of the 13 patients who had pain relief, 11 were in the treatment group and 2 in the control group. Is this evidence in favor of the treatment?
The null hypothesis says that the treatment does nothing; any difference between the two groups is due to the random assignment of patients to treatment and control.
The alternative hypothesis says that the treatment was beneficial.
Under the null hypothesis, the treatment did nothing different from the control, so among the 31 patients in the study, 13 would have had pain relief anyway, regardless of the assignment to groups.
To see which of the hypotheses is better supported by the data, we can find a P-value. This is the chance, under the null hypothesis, of getting data like the data that were observed or even more in the direction of the alternative. That is, the P-value is the chance of getting 11 or more of the “pain relief” patients in the treatment group, just by chance.
To find the chance that 11 or more of the “pain relief” group would have ended up in the treatment group, we just need a hypergeometric probability:
N = 31, the population size
G = 13, the total number of “pain relief” patients
n = 15, the size of the treatment group
g = 11 or more
sum(stats.hypergeom.pmf([11, 12, 13], 31, 13, 15))
0.0008299755046076283
That’s a very small P-value, which implies that the data support the alternative hypothesis more than they support the null. The treatment helped. This is consistent with the conclusion of the researchers and also with our own analysis in Data 8 – but all three analyses are different.
In Data 8 we simulated the difference between the two group proportions under the null hypothesis, by pooling the two groups and randomly permuting the pooled sample. Our conclusion was based on an empirical, approximate P-value.
The calculation here does not require simulation and produces an exact P-value.
This method is called Fisher’s exact test. That’s the same Sir Ronald Fisher who formalized tests of hypotheses, suggested cutoffs for P-values, and so on. The method can be used for any sample size and any randomized controlled experiment with a binary response.
6.4.6. Joint, Marginal, and Conditional Distributions#
The calculations above extend easily to samples that can come out in more than two categories. Consider a five-card poker hand dealt from a well-shuffled deck. Let
The hand can have cards other than hearts and spades, of course. Let
The SciPy module special allows you to calculate binomial coefficients, so let’s import it.
from scipy import special
The expression special.comb(n, k) evaluates to
def joint_prob(h, s):
if (h+s >=0) and (h+s <=5):
numerator = special.comb(13, h) * special.comb(13, s) * special.comb(26, 5 - h -s)
denominator = special.comb(52, 5)
return numerator / denominator
else:
return 0
k = np.arange(6)
joint_dist = Table().values('H', k, 'S', k).probability_function(joint_prob)
joint_dist
| H=0 | H=1 | H=2 | H=3 | H=4 | H=5 | |
|---|---|---|---|---|---|---|
| S=5 | 0.000495 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| S=4 | 0.007153 | 0.003576 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| S=3 | 0.035764 | 0.037195 | 0.008583 | 0.000000 | 0.000000 | 0.000000 |
| S=2 | 0.078031 | 0.126801 | 0.060864 | 0.008583 | 0.000000 | 0.000000 |
| S=1 | 0.074780 | 0.169068 | 0.126801 | 0.037195 | 0.003576 | 0.000000 |
| S=0 | 0.025310 | 0.074780 | 0.078031 | 0.035764 | 0.007153 | 0.000495 |
The distribution of marginal method:
joint_dist.marginal('H')
| H=0 | H=1 | H=2 | H=3 | H=4 | H=5 | |
|---|---|---|---|---|---|---|
| S=5 | 0.000495 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| S=4 | 0.007153 | 0.003576 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| S=3 | 0.035764 | 0.037195 | 0.008583 | 0.000000 | 0.000000 | 0.000000 |
| S=2 | 0.078031 | 0.126801 | 0.060864 | 0.008583 | 0.000000 | 0.000000 |
| S=1 | 0.074780 | 0.169068 | 0.126801 | 0.037195 | 0.003576 | 0.000000 |
| S=0 | 0.025310 | 0.074780 | 0.078031 | 0.035764 | 0.007153 | 0.000495 |
| Sum: Marginal of H | 0.221534 | 0.411420 | 0.274280 | 0.081543 | 0.010729 | 0.000495 |
But
stats.hypergeom.pmf(k, 52, 13, 5)
array([ 0.22153361, 0.41141957, 0.27427971, 0.08154262, 0.01072929,
0.0004952 ])
If you know how many spades are in the hand, then what is the conditional distribution of
joint_dist.conditional_dist('H', 'S')
| H=0 | H=1 | H=2 | H=3 | H=4 | H=5 | Sum | |
|---|---|---|---|---|---|---|---|
| Dist. of H | S=5 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| Dist. of H | S=4 | 0.666667 | 0.333333 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| Dist. of H | S=3 | 0.438596 | 0.456140 | 0.105263 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| Dist. of H | S=2 | 0.284495 | 0.462304 | 0.221906 | 0.031294 | 0.000000 | 0.000000 | 1.0 |
| Dist. of H | S=1 | 0.181761 | 0.410937 | 0.308203 | 0.090406 | 0.008693 | 0.000000 | 1.0 |
| Dist. of H | S=0 | 0.114250 | 0.337556 | 0.352232 | 0.161440 | 0.032288 | 0.002235 | 1.0 |
| Marginal of H | 0.221534 | 0.411420 | 0.274280 | 0.081543 | 0.010729 | 0.000495 | 1.0 |
Let’s see if we recognize these numbers. Remember that the
For an extreme case, look at the top row. Given that there are five spades in the hand, there can’t be any hearts. That is why the table says
Now suppose we are given that
by canceling factors of
This is the hypergeometric
stats.hypergeom.pmf(np.arange(5), 39, 13, 4)
array([ 0.18176071, 0.41093725, 0.30820294, 0.0904062 , 0.0086929 ])
These are the probabilities in the row corresponding to the given condition