16.1. Linear Transformations#
Linear transformations are both simple and ubiquitous: every time you change units of measurement, for example to standard units, you are performing a linear transformation.
16.1.1. Linear Transformation: Exponential Density#
Let
The parameter
That’s the cdf of the exponential
To summarize, if
You can think of the exponential
If
Here are graphs of the densities of
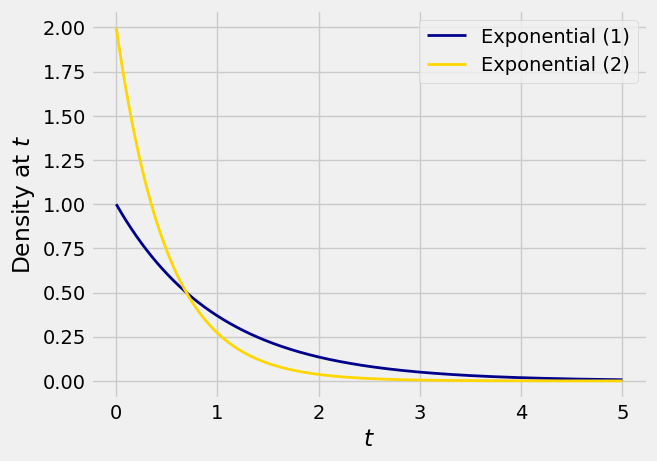
The formulas for the two densities are
Let’s try to understand the relation between these two densities in a way that will help us generalize what we are seeing in this example.
The relation between the two random variables is
For any
If we think of
Quick Check
If
Answer
See More
16.1.2. Linear Change of Variable Formula for Densities#
We use the same idea to find the density of a linear transformation of a random variable.
Let
Let’s take this formula in two pieces, as in the exponential example.
For
The linear function
This is a good way to understand the formula, and will help you understand the corresponding formula for non-linear transformations.
For a formal proof, start with the case
By the chain rule of differentiation,
If
Now the chain rule yields
Quick Check
(a) Write the density of
(b) Write the density of
Answer
(a) For all
(b) For all
16.1.3. The Normal Densities#
Let
Let
Thus every normal random variable is a linear transformation of a standard normal variable.
Quick Check
Let
Answer
16.1.4. The Uniform Densities, Revisited#
Let the distribution of
First it is a good idea to be clear about the possible values of
At
That’s the uniform density on